Hydra: An Overview of Features and Benefits
7 minutes
19
Hydra is a cutting-edge data management system that has been designed with the latest technology and innovation in mind. With its powerful features and unparalleled flexibility, it is rapidly becoming the go-to choice for businesses looking to revolutionize their data management processes. If you want to be in the loop, too, here is what you need to know.
Introduction to Hydra
Hydra is an open-source database management system (DBMS) designed to provide a highly scalable solution for managing large volumes of data.
It is an open-source Snowflake alternative that aims to solve problems related to data silos and inconsistent data sources. It provides a columnar storage engine with vectorized execution that integrates seamlessly with various database configuration options, including Windows and Linux. It can also support a wide range of databases, including structured and unstructured data sources, making it a versatile solution.
With Hydra, users can easily create a Docker image and run it on any platform without any issues. This is particularly useful for organizations that have a diverse range of systems and need to access their data from a consistent and reliable source. Additionally, Hydra’s ability to tag and categorize data makes it easier to identify and manage data from disparate sources, which is a crucial capability for organizations dealing with data silos.
Capabilities
In general, Hydra can be used to centralize, organize, and analyze large volumes of data, making it a valuable tool for a wide range of use cases.
Centralize
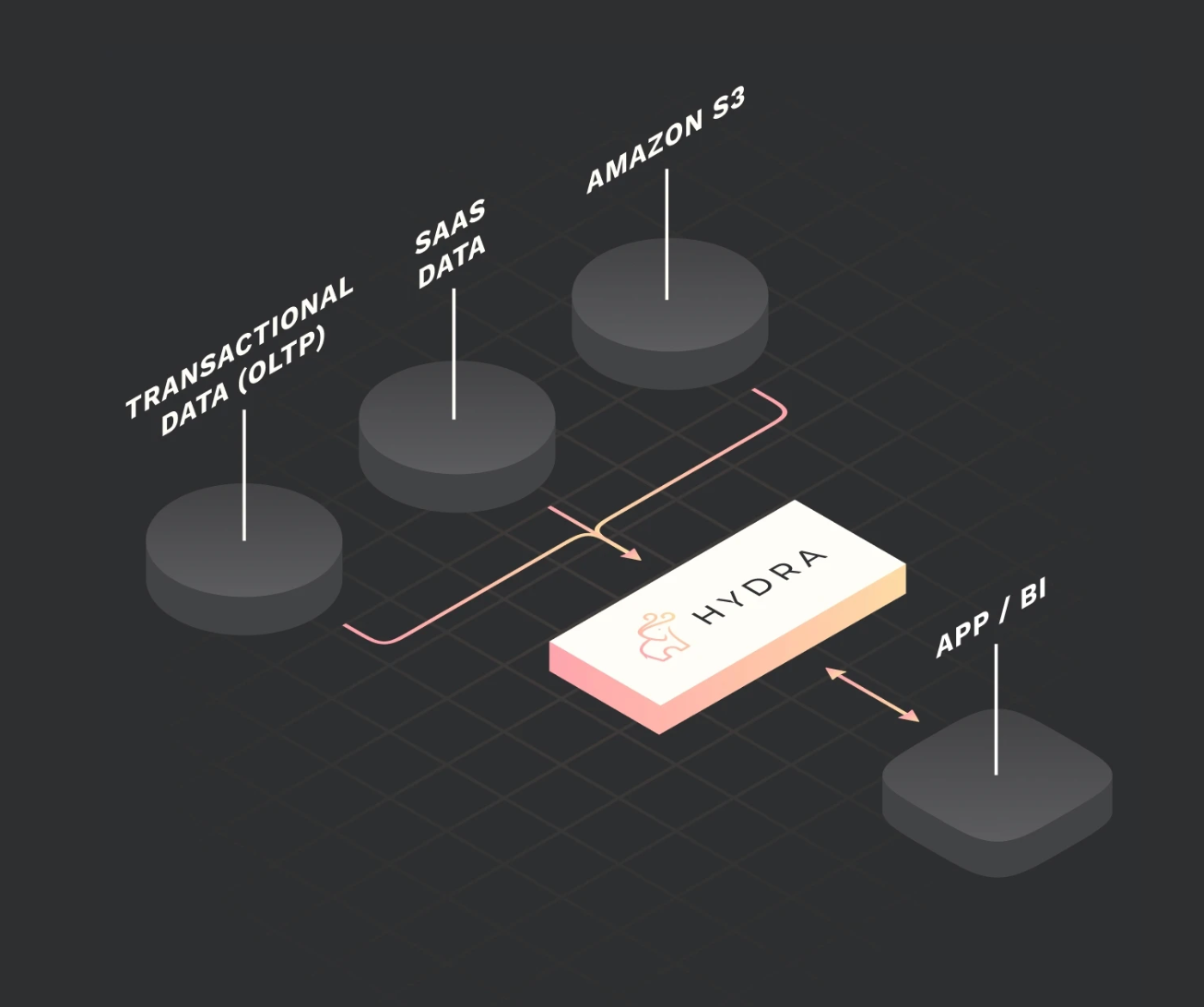
Hydra can be used as a centralized repository for storing and managing large volumes of data. This makes it a valuable tool for organizations that need to store and manage data from multiple sources, such as IoT devices, social media platforms, or e-commerce websites. By centralizing data in Hydra, organizations can gain a more complete view of their data landscape, which can be used to drive better business decisions.
Organize

Hydra’s support of flexible schema design makes it well-suited for organizing and managing complex datasets. This can be helpful for organizations that need to handle data with complex structures, such as financial or scientific data. Thus, these organizations can navigate and analyze their data more easily, driving better insights and improving decision-making.
Analyze

Finally, Hydra’s support of a wide range of data types, including JSON, BSON, and binary data, makes it valuable for analyzing large and complex datasets. Thus, it is well-suited for organizations that need to perform advanced analytics on their data, such as predictive modeling or machine learning. As a result, they can uncover insights that would be difficult or impossible to discover using traditional database systems.
Unique Features
One of the key features of Hydra is its support of vectorization, which allows for more efficient processing of data. This is especially important when working with large datasets, as traditional processing methods can be slow and inefficient. With vectorized execution, Hydra is able to perform complex calculations and analysis at lightning-fast speeds.
For example, let’s say you have a dataset with millions of rows and dozens of columns. With traditional processing methods, it could take hours or even days to perform certain calculations or generate insights. But with Hydra’s vectorized execution, these tasks can be completed in just a fraction of the time, allowing for better decision-making, problem-solving, and resource usage.
Database Setup Instructions
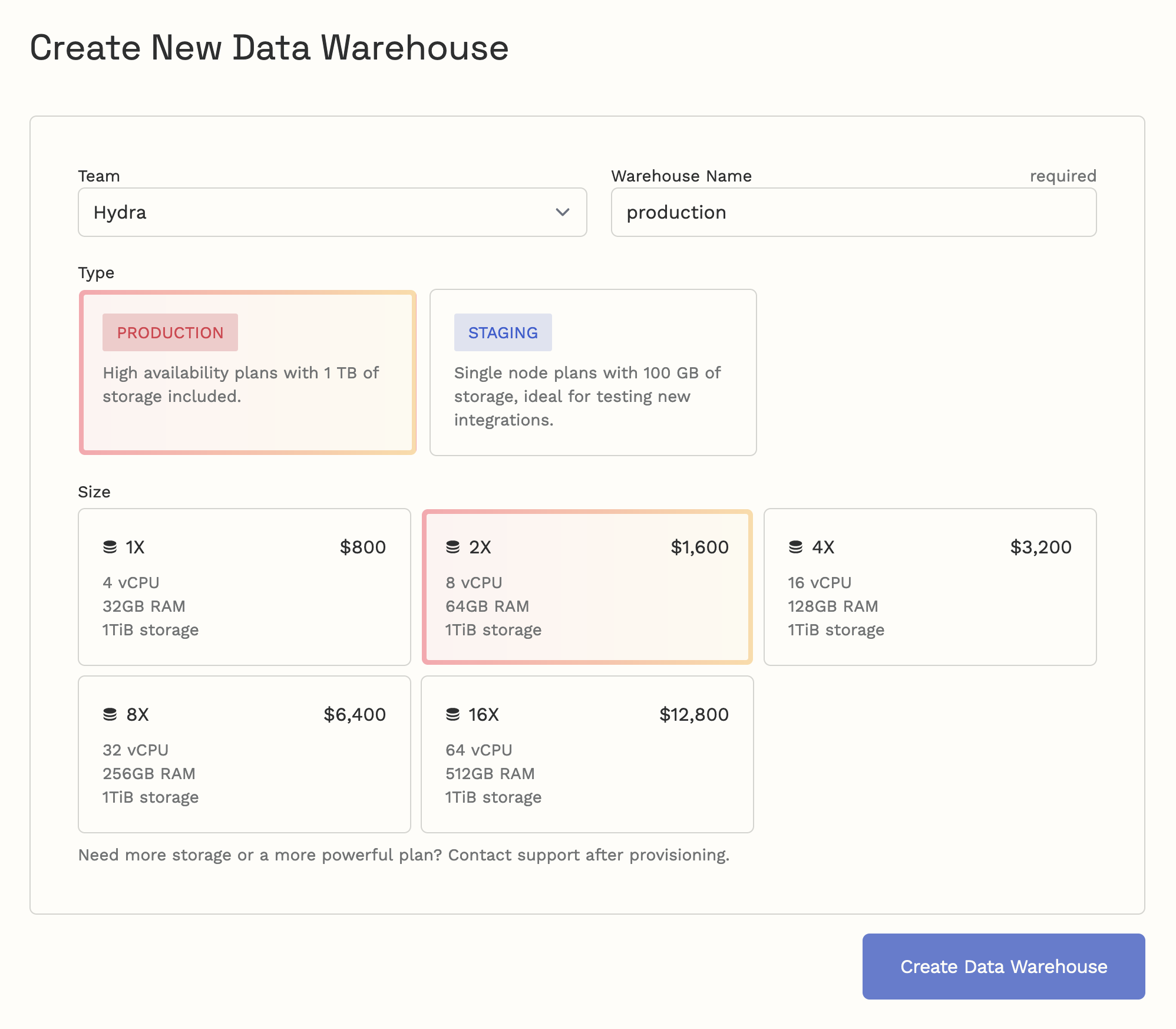
If you’re ready to set up Hydra, here are the steps to follow:
- Name your team. Every account is part of a team, so you should be using your company name or team name within your company. If you accept a team invite from a teammate, you will not see this step.
- Request a demo or proceed with a data warehouse of your choice.
- Provide a name that will be only for your own use.
- Pick your desired tier—all Production plans have HA (High Availability), while Staging plans do not. Production is better if availability is important for your use case.
- Pick your plan size. A 1X plan is usually the best place to start, and Hydra can always increase your plan later.
Once your Hydra warehouse is ready, the page will show your connection details and the very first metrics. If your Hydra is still not available after 15 minutes, something may have gone wrong, and you should contact support.
How to Load and Stream Data
Hydra provides multiple ways to load data into the warehouse from different sources, such as CSV files, S3, Postgres, Google Sheets, and Hydra Open Source.
Here’s how you can load data from a local CSV file:
- Open the Hydra dashboard and select Data Sources from the sidebar.
- Click + Add Data Source, and select CSV from the dropdown menu.
- Enter the name of the data source, choose the CSV file from your local machine, and provide the necessary details like delimiter, header row, etc.
- Click Create.
When loading data from S3, follow the same steps as above, but select S3 from the dropdown menu and provide the necessary details like AWS access key, secret key, bucket name, etc. For Postgres, you need to specify the host, port, database name, username, password, etc. For Google Sheets, you’ll need the sheet URL, an access token, a refresh token, etc. And for Hydra Open Source, you’ll need details like the Hydra Open Source API endpoint, access key, secret key, etc.
Additionally, Hydra supports data streaming using Apache Kafka, AWS Kinesis, and Google Pub/Sub. You can connect your ETL tool, Segment, or DBMS to one of these streaming platforms and then create a data source in Hydra using the respective platform. Once you have created the data source, Hydra will automatically start streaming data into the warehouse.
Data Modeling and Data Hygiene
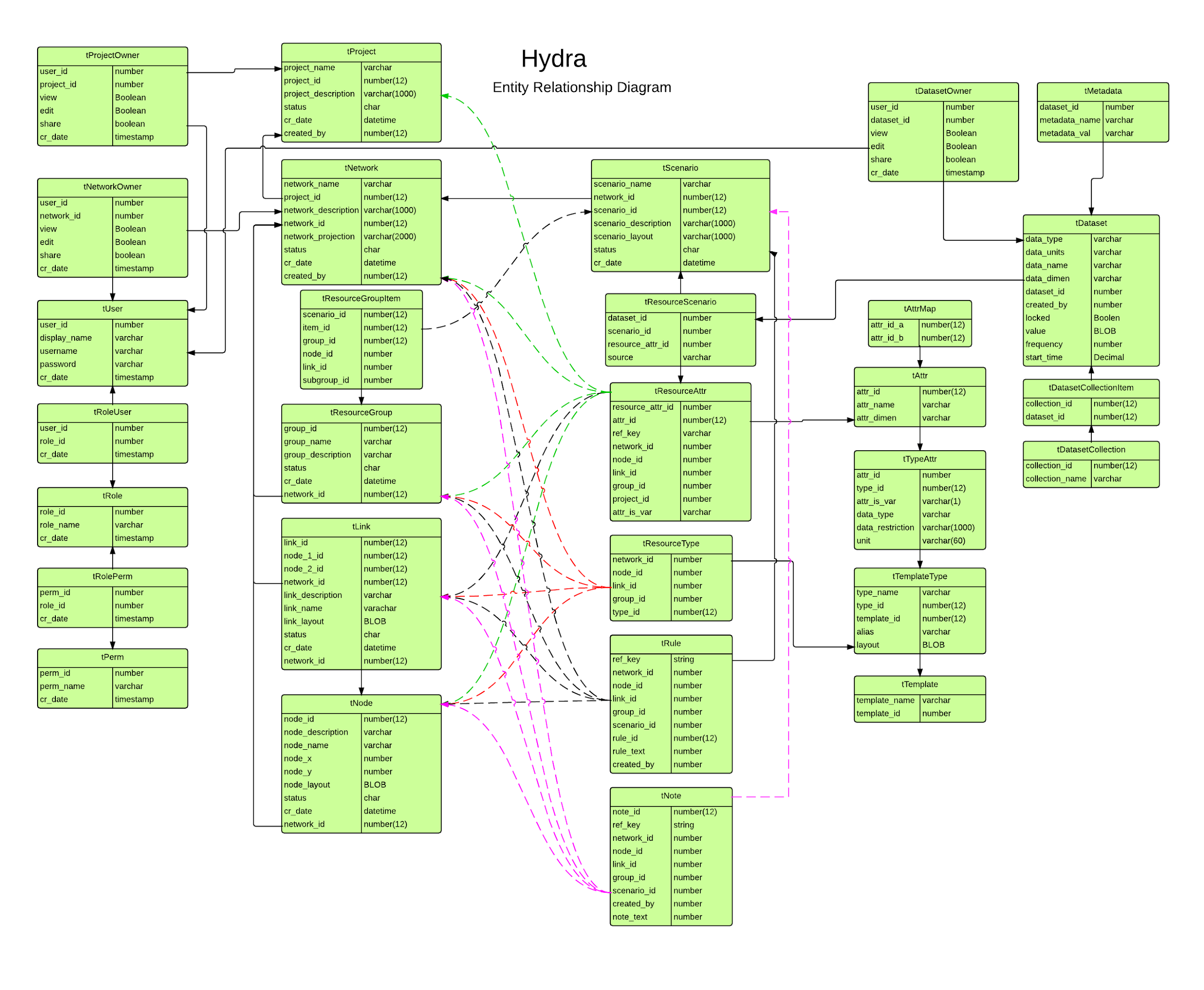
Hydra uses an intuitive data modeling system that allows users to create custom data models that perfectly fit their needs. This system is based on the Entity-Attribute-Value (EAV) model, which allows users to store data in a scalable format.
With Hydra, users can create entities, which represent the main objects in their data model, and then add attributes to each entity to define the specific properties of those objects. This allows users to store data in a highly granular and customizable format, making it easy to extract insights and analyze data in a way that is tailored to their specific needs.
As for data hygiene, one way to ensure Hydra data is reliable, consistent, and up-to-date is through the use of DBT. It allows users to define transformations and models in a modular and reusable way, which can be version controlled and deployed consistently and reliably.
Another way to ensure data hygiene in Hydra is through the use of ETL tools. These tools enable users to extract data from various sources, transform it to fit their specific needs, and load it into Hydra.
Different Ways to Analyze Data
Hydra offers several ways to analyze data, including using Postgres-native tools and third-party business intelligence tools. Some Postgres-native tools recommended for use with Hydra include psql, pgAdmin, Navicat for PostgreSQL, and PSequel. For business intelligence, some recommended tools include Metabase, Trevor, Looker, and Tableau.
Regardless of which tool is used, Hydra’s vectorized execution and OLAP capabilities allow for faster and more efficient analysis of data. This is especially important when working with large datasets, where traditional processing methods can be slow and cumbersome.
In addition to these tools, Hydra also allows for custom integrations and development, making it a versatile platform for data analysis. This means that organizations can tailor their data analysis approach to their specific needs and requirements, whether that involves using off-the-shelf tools or building custom solutions from scratch.
Pros and Cons of Using Hydra
Pros:
- Open-source
- User-friendly interface
- Highly customizable
- Scalable
Cons:
- Steep learning curve
- Limited support
- Limited third-party integrations
Conclusion
Overall, Hydra is an exciting new option for organizations looking for a reliable and consistent data source with advanced features like columnar storage, vectorized execution, and OLAP capabilities.
Whether you’re working with Windows or Linux or dealing with structured or unstructured data, Hydra is a powerful solution that can help you overcome even the most challenging data-related problems.
Of course, as with any technology, there may be some issues or challenges to overcome when using Hydra. However, its robust feature set and support of a wide range of platforms and configurations make it a powerful tool for organizations that need to manage large amounts of data and perform complex analysis.

We convert raw data into meanigful insights for you to make the best decisions.
Featured Articles
-

Top 5 Data Visualization Tools in 2023
A simplified representation of complex data is key for any data-driven business. Raw data must be turned into a cohesively formatted visual that is…
Read more -

SnowFlake: The Best Data Warehousing and Prescriptive Analytics Solution
Data Warehouse as a Service, or DWaaS, has gained much popularity in the past decade. It is a service primarily provided by Snowflake Inc,…
Read more -

Simple Mobile Analytical Stack: Firebase + BigQuery
Developing reliable and high-quality mobile and web applications requires a lot of dedication and, more importantly, a powerful and feature-rich development platform. Firebase, provided…
Read more