Relational databases handle two kinds of work: analytical queries and transactional writes. This article is about the second kind: what it means when a transaction “succeeds” or “fails,” and why those guarantees aren’t free.
In This Article
A transaction is several read and write operations grouped into one logically indivisible unit. The textbook example is a money transfer: you take funds from one account and put them in another. It looks like one action to the user, but underneath it’s at least two writes that must either both happen or both not happen. The properties that make this work are abbreviated ACID — an acronym that has nothing to do with chemistry.
A — Atomicity
Atomicity says all the operations inside a transaction either complete in full or have no effect at all. No partial state. In most database engines you mark the boundaries explicitly with START TRANSACTION (or BEGIN) at the start and COMMIT to finalize, or ROLLBACK to cancel.
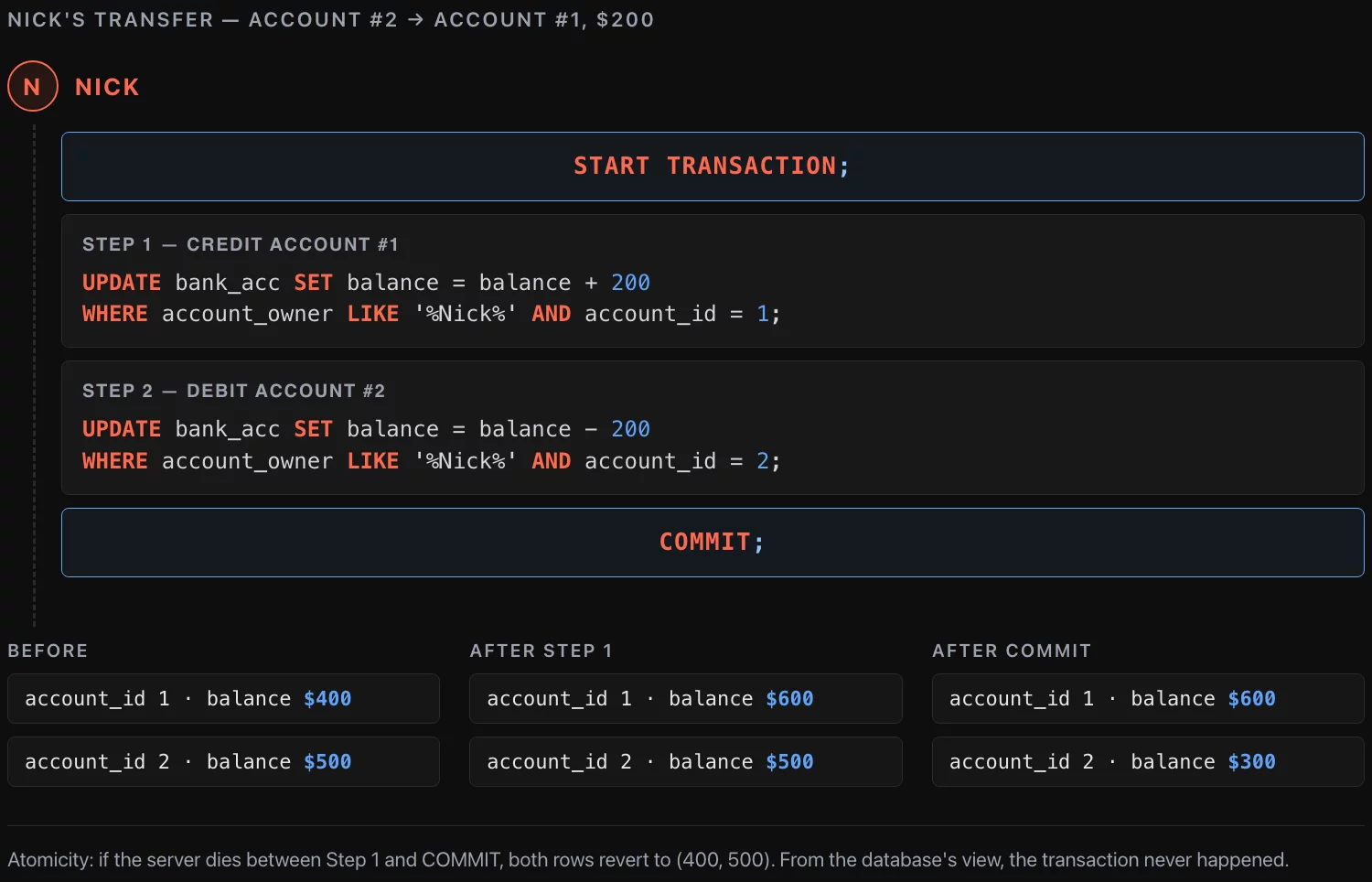
Say Nick has two accounts at the same bank. He moves $200 from account #2 to account #1:
START TRANSACTION;
UPDATE bank_acc SET balance = balance + 200
WHERE account_owner LIKE '%Nick%' AND account_id = 1;
UPDATE bank_acc SET balance = balance - 200
WHERE account_owner LIKE '%Nick%' AND account_id = 2;
COMMIT;If the server loses power after the first UPDATE runs but before COMMIT, atomicity guarantees that both accounts revert to their previous balances ($400 and $500). From the database’s point of view, the transaction never happened.
C — Consistency
Consistency means certain assertions about the data must hold before and after every transaction. For Nick’s transfer, the assertion is: money moving between two accounts of the same owner shouldn’t change the total.
Before: $400 + $500 = $900. After: $600 + $300 = $900.
The invariant holds. If a transaction’s writes would violate one of these assertions, the database refuses to commit. In practice, classical relational databases enforce only the cheap, structural invariants (primary keys, foreign keys, CHECK constraints). Business invariants are still your job — but the framing is the same.
I — Isolation
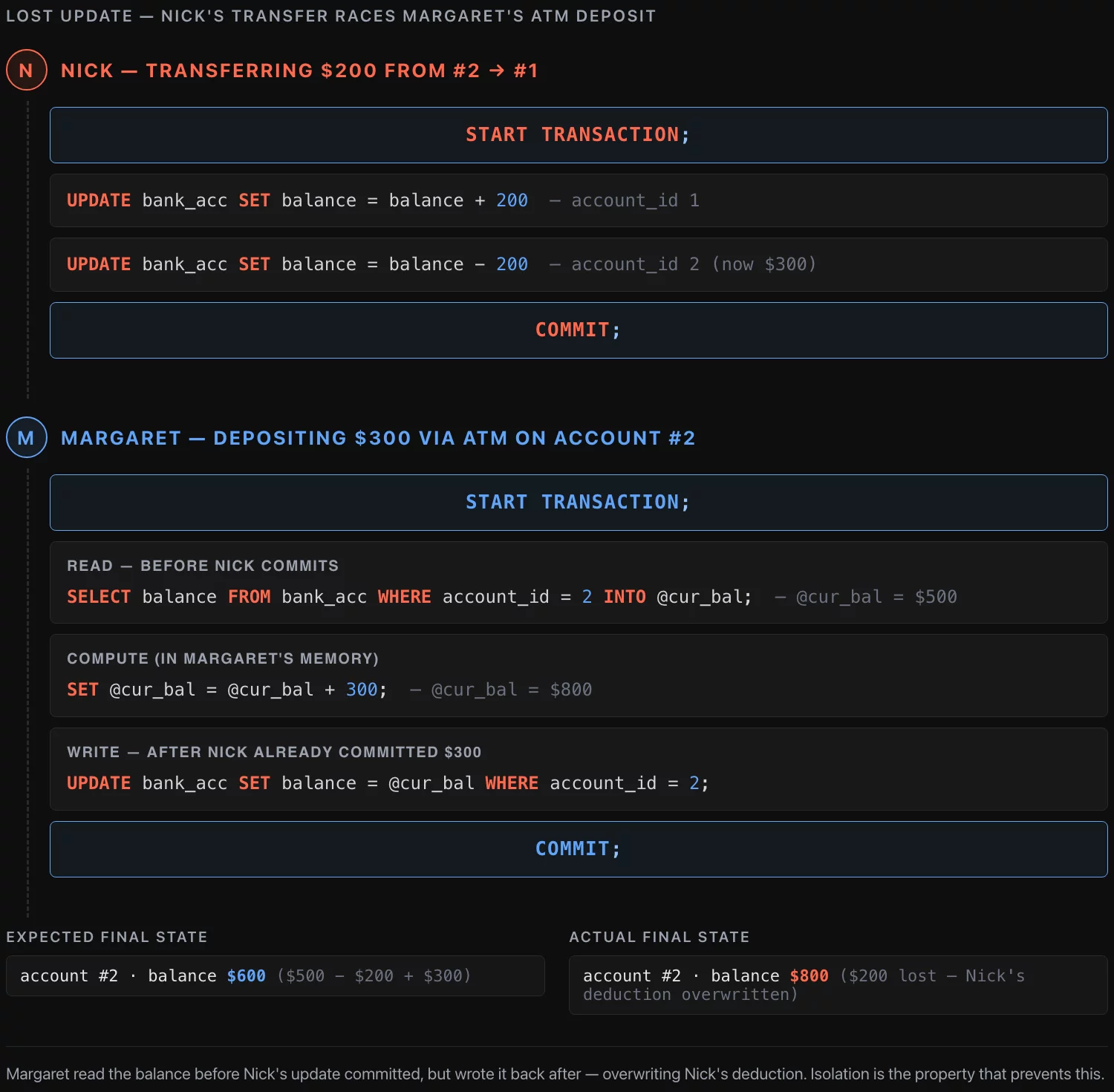
Isolation is what keeps concurrent transactions from corrupting each other. The classic failure mode is the lost update.
While Nick’s transfer is in flight, his wife Margaret walks up to an ATM and deposits $300 into account #2. Her transaction is naive: read the current balance, add 300, write the result back.
-- Margaret's transaction
SELECT balance FROM bank_acc WHERE account_id = 2 INTO @cur_bal;
SET @cur_bal = @cur_bal + 300;
UPDATE bank_acc SET balance = @cur_bal
WHERE account_owner LIKE '%Nick%' AND account_id = 2;
COMMIT;If Margaret’s read happens before Nick’s UPDATE on account #2 but her write happens after it, she reads $500, adds $300, and writes $800 — overwriting Nick’s deduction. The correct final balance for account #2 is $500 − $200 + $300 = $600, but the table now says $800. Nick’s $200 vanished from the system.
D — Durability
Once a transaction commits, its writes must survive every kind of crash short of the disk being destroyed. For a single-node database that means writing to persistent storage (and waiting for the write-ahead log to be flushed before returning COMMIT). For a replicated system it usually means writing to a quorum of replicas. The whole point is: when the client sees COMMIT OK, the change is permanent.
Isolation levels
There are four standard levels, in order of weakest to strongest.
READ UNCOMMITTED
The weakest level allows a transaction to read changes that other transactions have made but not yet committed — dirty reads. It does, however, prevent dirty writes: a transaction must wait if it tries to modify a row that another open transaction is in the middle of modifying.
Practical scenario: Nick spends $100 from account #1 in a long-running transaction. Margaret simultaneously deposits $100 into the same account through the ATM. Margaret’s UPDATE blocks until Nick’s transaction commits or rolls back. No interleaving of writes; reads are still unsafe.
READ COMMITTED
A transaction only reads committed data. This blocks both dirty reads and dirty writes.
The implementation has two parts:
- Preventing dirty writes: when a transaction modifies a row, the database takes an exclusive lock on it. Other transactions trying to modify the same row wait. Reads of that row still go through.
- Preventing dirty reads: the database keeps the previous version of every modified row visible to concurrent readers until the modifying transaction commits. While Nick’s
UPDATEis in flight, Margaret’sSELECTsees the old $500, not the in-progress $300.
READ COMMITTED is the default in PostgreSQL, Oracle, and SQL Server, and is good enough for the large majority of real workloads.
REPEATABLE READ
A long-running transaction can read a row, have it modified by another transaction in the meantime, and then read it again with a different value. That’s a non-repeatable read — the same query returns different answers within the same transaction.
A version with a wider scope is the phantom read: a SELECT returns one set of rows, another transaction inserts new rows that match the predicate, and a re-SELECT returns a larger set.
Concrete scenario: while Nick’s transfer is mid-flight, an auditor runs a long report that sums every account. The auditor reads account #2 before the deduction (sees $500), then reads account #1 after the addition (sees $600). The report total is $500 + $600 = $1,100 — neither the pre-transfer total ($900) nor the post-transfer total ($900).
REPEATABLE READ solves this by reading from a snapshot that’s frozen at the start of the transaction. The auditor sees only changes committed before their report began.
#### MVCC
The dominant implementation of REPEATABLE READ is multiversion concurrency control (MVCC). The database keeps multiple versions of each row. Every version is stamped with:
- the transaction ID (
txid) that created it - the
txidthat deleted it (if any)
Every new transaction gets a unique, monotonically increasing txid. A transaction with id T only sees row versions whose created_txid ≤ T and whose deleted_txid is either empty or greater than T.
So if the auditor’s transaction is txid 9 and Nick’s transfer is txid 10, the auditor sees the original $400 and $500 throughout the report, even after Nick commits. The auditor’s totals are consistent because they’re reading a single point in time.
SERIALIZABLE
The strongest level guarantees that concurrent transactions produce the same result as some sequential execution. Three implementation strategies are in use:
1. Actual serial execution. Run every transaction one at a time on a single thread. Surprisingly viable for very short transactions that fit in memory — Redis and some financial systems do this. Hopeless if any transaction has to wait on disk.
2. Two-phase locking (2PL). Reads acquire shared locks; writes acquire exclusive locks. Any number of readers can share a row, but a writer needs exclusive access. If transaction A is reading rows that transaction B wants to modify, B waits for A to finish (or vice versa). Correct, but contended workloads can deadlock or stall.
3. Serializable Snapshot Isolation (SSI). An optimistic newer approach. Transactions read from an MVCC snapshot and write freely, assuming there’s no conflict. At commit time the database checks whether anything they read was modified by another committed transaction in the meantime. If so, the optimistic transaction is rolled back and must be retried. PostgreSQL’s SERIALIZABLE level uses SSI; CockroachDB does too.
SERIALIZABLE correctness costs throughput. SSI is currently the best trade-off — strong guarantees without the lock-storm of 2PL, paid for in occasional retries.
How this lands in modern data engineering
The four-letter mnemonic is the same. The asterisks have moved.
- PostgreSQL, Oracle, SQL Server: full ACID, all four isolation levels, well-understood failure modes. The reference.
- Snowflake, BigQuery, Redshift: ACID per statement; snapshot isolation by default for reads. Multi-statement transactions exist but most ELT tools skip them.
- ClickHouse: append-mostly by design. Transactional support exists in recent versions but isn’t the default — the engineering culture leans on idempotent ingestion and
ReplacingMergeTreeinstead. We covered the trade-offs in detail in ClickHouse in Consulting Practice. - Iceberg, Delta Lake, Hudi: ACID on top of object storage (S3, GCS). Atomic commits via metadata pointers; snapshot isolation through version manifests. The most consequential change in data lakes in the last five years.
ACID violations in modern stacks rarely look like the textbook examples. They look like a dbt run that races a CDC stream into the same table. Or a long-running BI query that sees half a refresh. Or a buffer-write engine that loses ninety seconds of events when the node dies. The vocabulary still applies — you just have to map it onto pipelines instead of bank accounts.
Takeaway
ACID is a contract about what happens when something fails halfway through a write. Atomicity says the write is all-or-nothing. Consistency says invariants hold across writes. Isolation says concurrent transactions don’t corrupt each other. Durability says committed writes survive crashes.
The interesting work, in 2026, is mapping those guarantees onto warehouses and lakes that weren’t built with the textbook in mind. SSI is the most promising direction for getting strong correctness without paying the historical performance tax.
![[REVIEW] Looker Studio vs Power BI 2026](https://valiotti.com/wp-content/uploads/2026/06/looker-studio-vs-power-bi-2026-hero-768x512.png)

