The era of traditional analytics solutions is over. In a world where data is king, organizations need to extract meaningful insights from it quickly and efficiently to stay on top. And now, they need a powerhouse solution that combines advanced capabilities and delivers unprecedented speed, scalability, and flexibility.
In This Article
Let’s talk about the modern analytics stack and the tools it uses to unlock the full potential of data.
How We Got Here: The Rise of the Modern Data Stack
The rise of the modern data stack can be attributed to several factors that, together, fundamentally changed the way we deal with data.
First, the explosion of data has created a pressing need for advanced analytics tools that can handle large, hard-to-manage volumes of data. But older stacks were not designed for this. Businesses are also collecting data from more sources than ever, with social media, mobile devices, and IoT devices entering the picture.
Second, the limitations of siloed data are becoming more apparent over time. In the past, data was often siloed in different departments and systems, which hardly provided a comprehensive view of the business. The modern analytics stack addresses this challenge by bringing all data together in one place.
Third, and it’s already mentioned, is the need to make decisions quickly and with confidence. The data stack now needs to process data in real time, which wasn’t a priority in the past.
When Should You Upgrade to the Modern Data Stack?
One common sign of an outdated data analytics stack is static information. If your analytics tools can’t provide dynamic and interactive data visualizations with real-time visibility, you may not be able to identify trends and patterns when needed. That defeats the purpose of an analytics stack, which is supposed to analyze data quickly to support timely decision-making.
Another indicator is the lack of customization and personalization. In today’s business landscape, you need your analytics tools to meet specific needs and provide tailored insights. If that’s not offered, the data stack may need an upgrade.
Ultimately, organizations need to work smarter, not harder. While quick fixes may temporarily fill gaps in their analytics capabilities, investing in a comprehensive solution with a reliable architecture and a set of modern tools is often the better answer.
What Makes the Modern Analytics Stack Different?
The modern analytics stack is different from traditional analytics in several ways:
- Cloud-based infrastructure. Businesses can store and process data on remote servers rather than on-premise. This allows them to scale up or down their infrastructure as needed without worrying about physical hardware costs.
- Decoupled architecture. Different components of the stack are separated and can be updated independently. So, organizations aren’t locked within a single vendor’s technology stack.
- Big-data handling capabilities. This allows businesses to make sense of vast amounts of data.
- Real-time data processing. Finally, this makes it possible for businesses to respond quickly to changing market conditions or customer needs.
Analytics Stacks for Different Needs
By definition, an analytics stack is a set of key components that work together to form a data workflow and provide business users with the necessary tools and resources. Depending on the needs of the organization, you may require different stack elements to support your particular data sources and analytical processes.
To give you a general idea of what a dependable analytics infrastructure may look like, here are some common components and tools:
Data Collection
The first thing on the agenda is gathering data from various sources, processing it, and storing it in a central repository. Chances are you are dealing with large volumes of raw data from multiple sources, like most modern businesses. This requires a robust data pipeline that can handle data transformation, data quality, and data governance.
Here are a few tools that can facilitate this process:
Apache Kafka

Apache Kafka is a popular tool for collecting and processing real-time data streams from different sources. It provides a simple publish-subscribe model. In other words, data producers publish messages on a topic, and data consumers subscribe to the topic to receive the messages.
One of the key advantages of using Kafka for data collection is its fault-tolerant architecture, which is perfect for building scalable data pipelines. The data streams are partitioned and distributed across multiple nodes, which ensures that the system can handle failures and scale horizontally as the data volumes grow.
Apache Nifi

Apache Nifi can come into play once the raw data has been collected and needs to be transformed into a usable format.
Nifi is a powerful data integration tool for transforming and enriching raw data. With Nifi, data can be cleansed, enriched, and transformed into a format that is suitable for downstream systems. It also provides features that ensure that the data is accurate and reliable.
Airflow + dbt
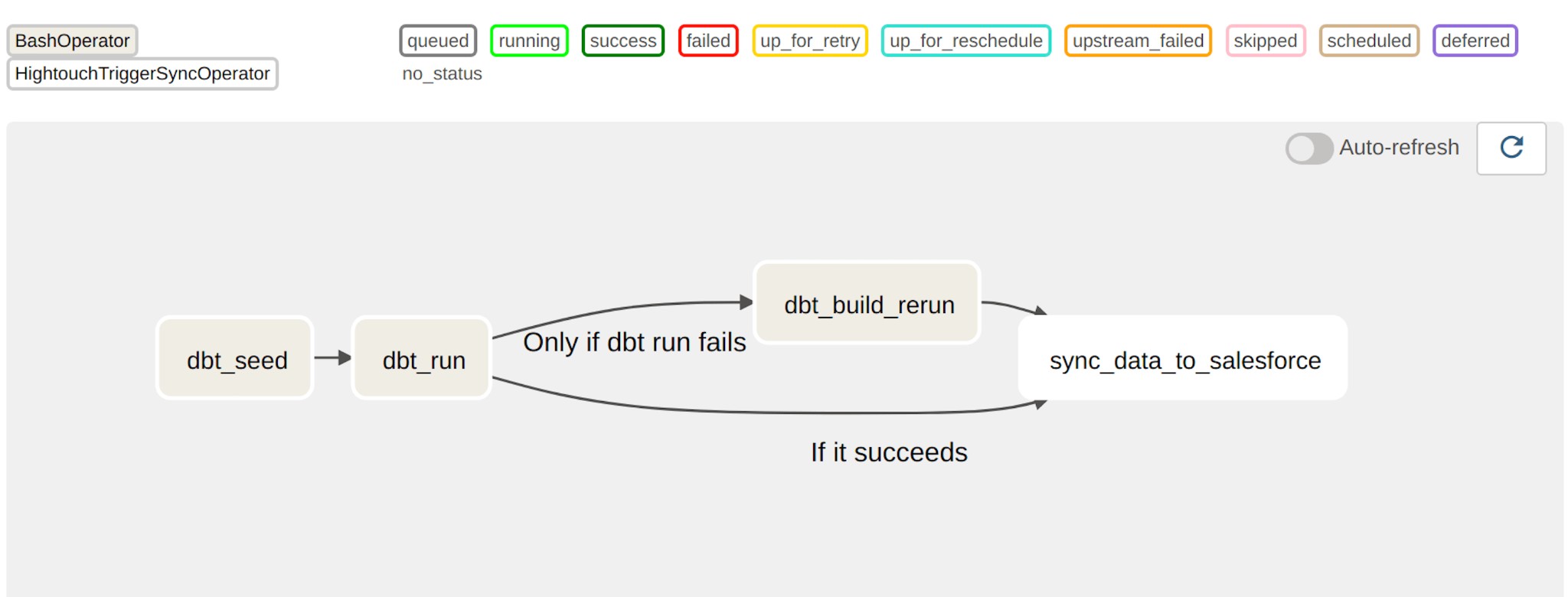
Airflow plus dbt is a popular combination for a modern data stack. Airflow is a platform for creating and scheduling complex workflows, while dbt transforms data using SQL.
Here is what it means in practice: Airflow allows businesses to define workflows as code, which can be version-controlled and managed through a code repository. This makes it easy to collaborate with team members and maintain a consistent approach to data pipeline development. Dbt provides a powerful SQL-based transformation engine that allows businesses to transform raw data into a format that can be used for analytics.
Data Storage
It’s not uncommon for companies to store terabytes or even petabytes of data. Obviously, this requires a robust and scalable storage solution like:
Clickhouse
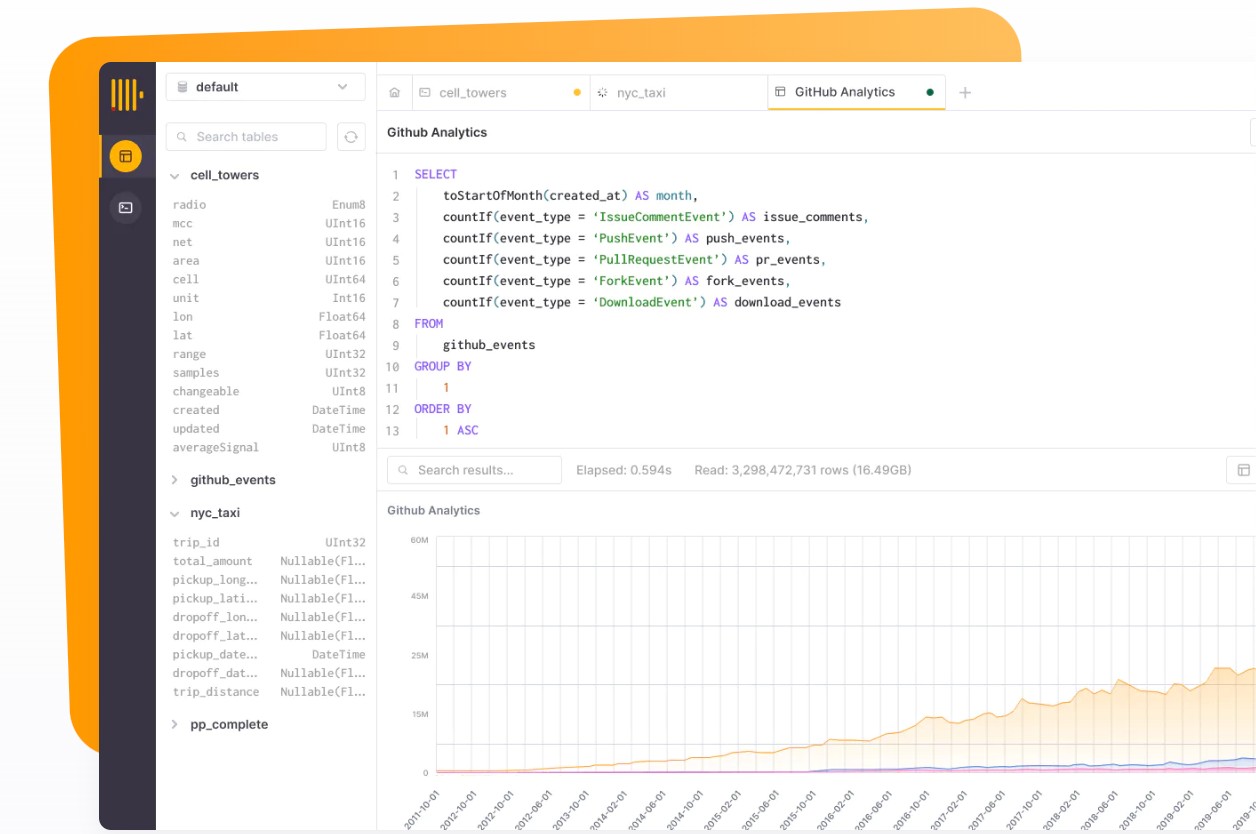
Clickhouse is an open-source columnar database that is widely used for storing data in modern analytics stacks. This is due to its unique architecture (columns rather than rows) and performance characteristics. It also uses a highly compressed data format, which reduces the storage space required to store data.
Clickhouse can handle large data sets and supports real-time data ingestion, which makes it a perfect choice for data warehousing and handling the high-speed data generated by modern applications.
BigQuery
BigQuery is a cloud-based data warehouse whose biggest benefit is its ease of use. It is a fully managed service, so it handles all of the infrastructure and administration tasks required for storage and management. This, in turn, allows data analysts to focus on key tasks without worrying about the underlying infrastructure.
Data stored in BigQuery is organized into tables, but it also supports nested and repeated fields for more complex structures.
PostgreSQL
PostgreSQL is a powerful open-source relational database that is commonly used for data warehousing. It offers advanced functionality, which includes indexing, data partitioning, and query optimization, and features a vast ecosystem of plugins and extensions for enhanced functionality.
It’s important to mention that Clickhouse, BigQuery, and PostgreSQL can all be used to store data in data warehouses as well as data lakes. This results in a unified approach to data management across multiple data storage systems. Plus, a data lake is better for storing data from social media, sensors, and other sources that may not fit into traditional databases.
Data Processing
This is a critical component of the data lifecycle. The processing stage can involve data cleaning and preparation, integration and transformation, enrichment, and more. The ultimate goal is to ensure that the data is of high quality and can be used for analysis. However, in some cases, data transformation may be handled during previous stages of the workflow.
With that said, let’s talk about the tools and frameworks to handle processing tasks efficiently.
Apache Spark
One of the most popular tools for processing data is Apache Spark. Spark is an open-source framework that supports a variety of data sources and provides a number of built-in libraries. It also supports multiple programming languages, including Java, Python, and Scala, so it’s suitable for data analysts with different skill sets.
Spark’s distributed computing architecture is another key advantage. This means processing large datasets simultaneously across multiple nodes.
Pandas + NumPy
Another popular choice is the Python library Pandas, along with its complementary library NumPy.
Pandas is designed to handle data manipulation and analysis tasks, while NumPy provides support for mathematical operations and scientific computing. Together, these libraries provide a powerful toolset to handle structured and unstructured data and perform mathematical operations.
SQL

SQL is widely used for processing tasks because it’s simple, flexible, and efficient. Speaking of efficiency, its ability to perform set-based operations in a single query is what reduces manual processing.
Some of the key features of SQL are data retrieval (from one or more tables in the database), modification (updating, adding new data, deleting), integrity (ensuring that data meets specific requirements), aggregation (performing calculations on groups of data), and joins (combining data based on common fields or relationships).
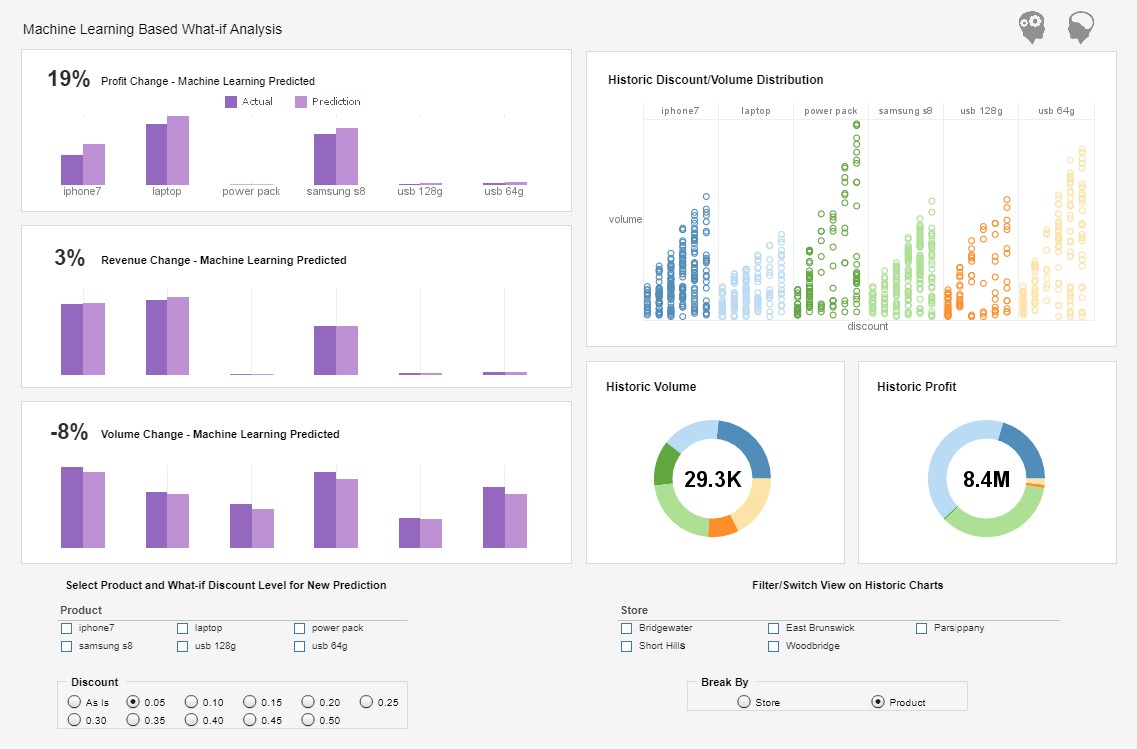
Machine Learning
In the case of machine learning, data engineers use algorithms that can learn from data and make predictions or decisions based on that learning. This point is an umbrella term for various processes, including automation tools for data analysis, predictive models, natural language processing (sentiment analysis, text classification, and entity recognition), anomaly detection, etc. The goal of such data tools is to extract insights that would be difficult or impossible to identify through traditional methods.
Here are a few options for data teams:
Scikit-learn
Scikit-learn is a Python library that provides a wide range of algorithms and tools for building and evaluating machine learning models. In the context of a modern data stack, it’s used as a core component for developing predictive models and integrating them into larger data pipelines.
Scikit-learn is easy to integrate with other popular libraries in the Python ecosystem, a few examples being Pandas for data manipulation and visualization libraries like Matplotlib and Seaborn. This integration allows for seamless processing and analysis.
TensorFlow + Keras
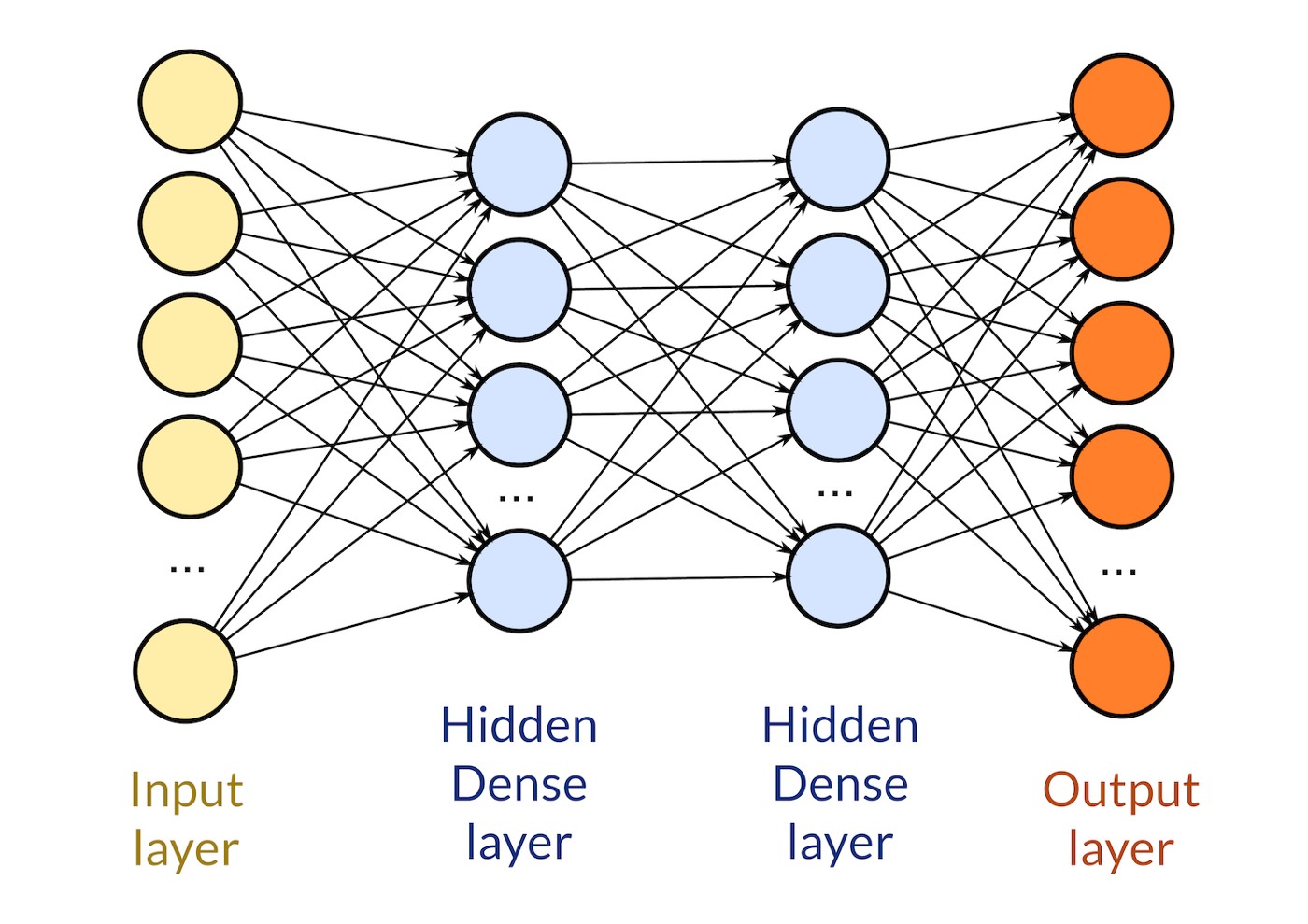
TensorFlow and Keras are deep learning libraries created for building complex models and accomplishing tasks like image classification, natural language processing, and time-series analysis.
Now that large datasets and computationally intensive models are common in business, this combination is especially handy. It doesn’t lose any efficiency even when handling large datasets and performing complex computations across multiple devices and processors.
Amazon SageMaker
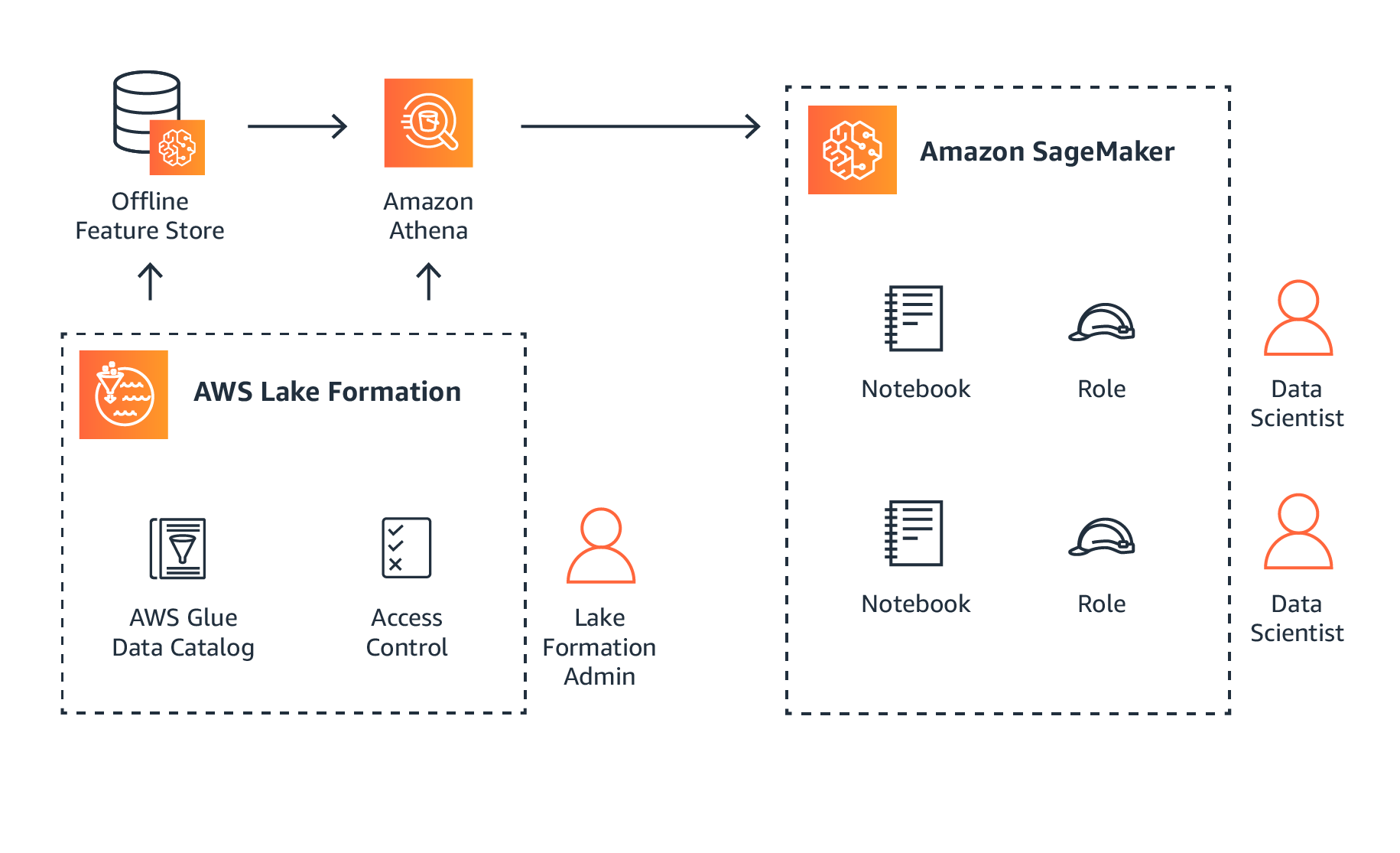
Amazon SageMaker is a fully managed machine learning service that is well-suited for numerous data analytics use cases.
Not only does it automate common data-related tasks, but it also simplifies the very process of training models. SageMaker automates many of the repetitive tasks involved in building and training machine learning models, so it will be easier to incorporate into your stack than most tools.
Business Intelligence
Business intelligence tools and platforms are integral for presenting data and data-driven insights in a way that is easily understood by business stakeholders. This stage involves a range of processes, including data exploration through interactive dashboards, reports, and visualizations, self-service analytics for non-technical business users, and real-time analytics to make rapid decisions.
Here is what business teams can use:
Power BI

Power BI is one of the most widely used reporting and analytics platforms out there. Depending on the business need, you can use it to connect to various data sources, transform and shape the data, create interactive visualizations, and share insights with others. Once you create real-time dashboards or generate automated reports, you can embed them into other applications or access them via the web or mobile devices.
The good news for non-tech users is that with Power BI, they can simply ask natural-language questions to get insights from their data.
Looker
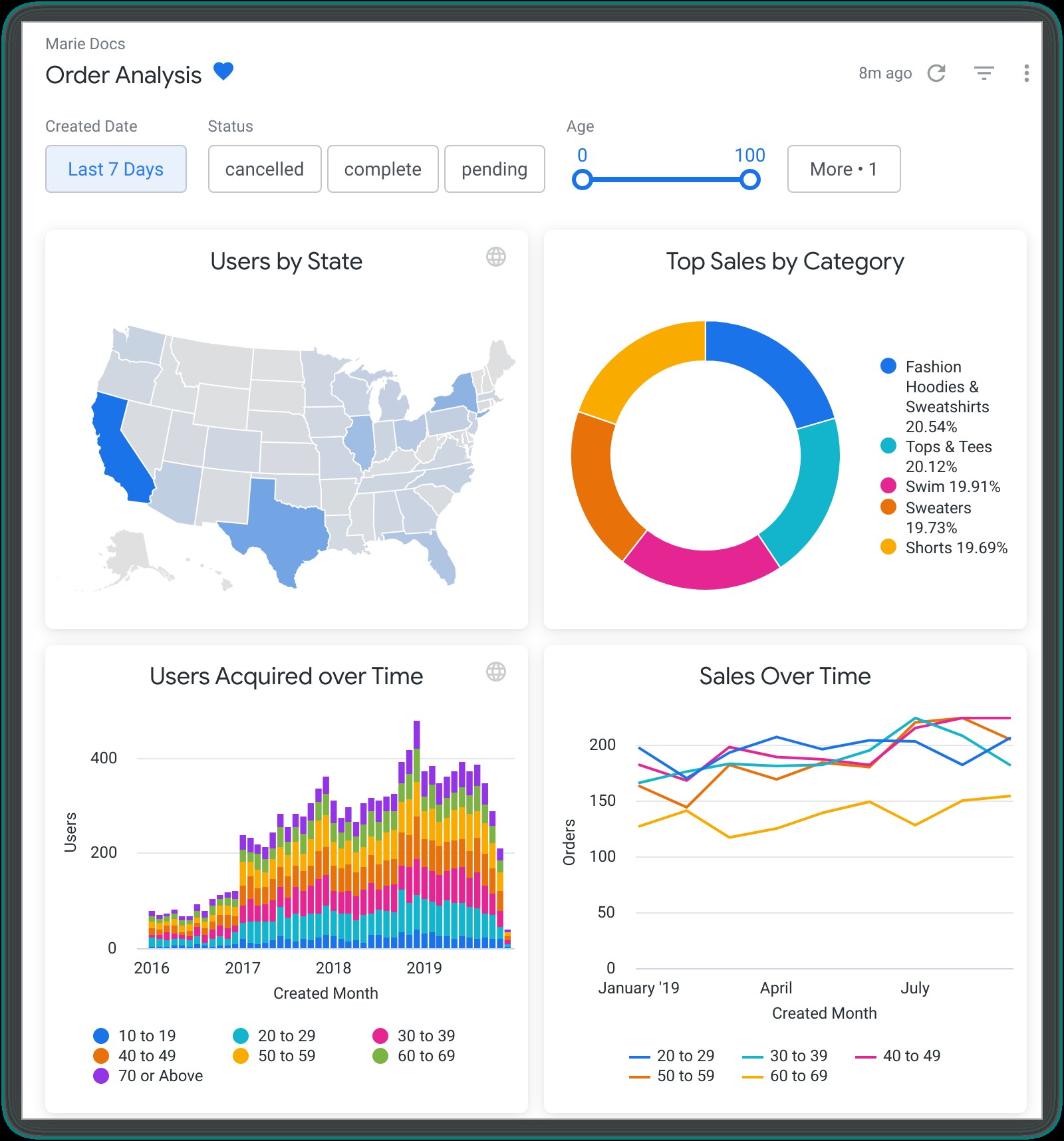
Looker provides users with a self-service environment to create dashboards, reports, and visualizations. The value for the user comes from valuable insights without having to rely on technical support.
What sets Looker apart is its unique modeling language—LookML. LookML allows analysts to define the relationships between different sources and create reusable models for the rest of the organization. This ensures a standardized approach where everyone is working with the same data model and there is minimal risk of errors.
Tableau
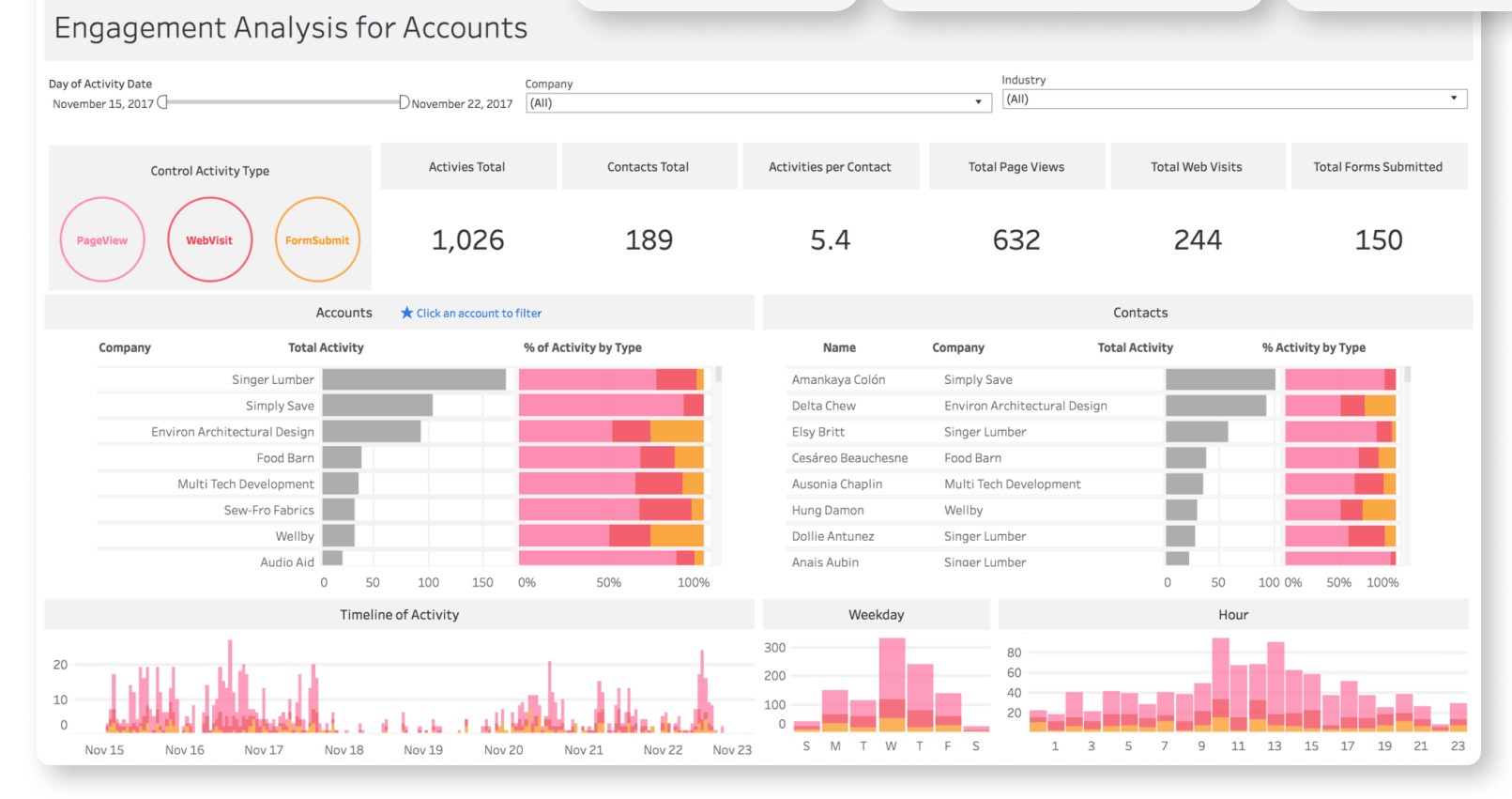
Finally, we have Tableau, a leading data tool for exploring data visually. With its intuitive drag-and-drop interface, users can quickly and easily build dashboards, reports, and charts from on-premise databases, spreadsheets, or web-based data.
The tool offers collaboration features so that teams can cooperate in real time, enabling them to make decisions based on the most up-to-date data. This is especially important for organizations where decision-making is time-sensitive and requires fast access to the most relevant information.
How Hard Is It to Set Up a Data Stack?
You can certainly say that setting up a data analytics stack today can be a complex process that requires significant technical expertise. But the process can be made more manageable if you make the right considerations:
- Identify the business needs and goals. For this, you need to understand the data that will be processed, the types of insights you need, and the specific use cases.
- Choose the right tools and technologies. You’ve seen a few examples above, but this step still requires a deep understanding of the available options and their capabilities.
- Design the architecture. For this step, you need to determine how the different components will work together, how data will flow through the system, and how the system will be secured.
- Set up. This may involve deploying servers, configuring databases, and integrating different tools and technologies.
- Test and adjust. Any issues you identify need to be addressed, and the system, on the whole, may need to be optimized for performance and scalability.


