ETL Processes Became 5 Times Faster as a Result of a Refined Data Warehouse: Twinero Case
Modernized a FinTech lender's data warehouse — ETL processes became 5x faster. Replaced legacy Pentaho stack with Python/dbt/Airflow, reducing maintenance overhead by 60%
Modernized legacy data stack — ETL processes 5x faster, maintenance overhead reduced by 60%. Replaced Pentaho with Python/dbt/Airflow.
The Challenge
Twinero, a Spanish fintech company offering short-term microloans, had built their data warehouse using ETL processes based on Pentaho IDE — a legacy tool that generated Windows-specific .xml configuration files running on Unix servers. This architectural mismatch created fragile pipelines that were slow, error-prone, and increasingly difficult to maintain as the business grew.
Beyond the technical debt, the outdated infrastructure was holding back the business. Reports were slow to generate, errors in data transformation were common, and the analytics team spent more time debugging pipelines than analyzing data. Twinero needed a complete modernization of their data infrastructure — not just patching the existing system, but rebuilding it with modern tools and best practices.
The business risk was growing daily. Twinero was a regulated fintech company, which meant reporting accuracy wasn’t just a nice-to-have — it was a compliance requirement. Errors in loan portfolio analytics could lead to regulatory issues, misreported risk metrics, and poor lending decisions. The legacy system’s fragility meant that even minor changes (a library update, a schema change) could cascade into report inaccuracies that might go undetected for days. The team was spending 40% of their time on pipeline maintenance — time that should have been spent on actual analysis and insight generation for the lending business.
Our Approach
We executed a comprehensive data infrastructure modernization in three phases:
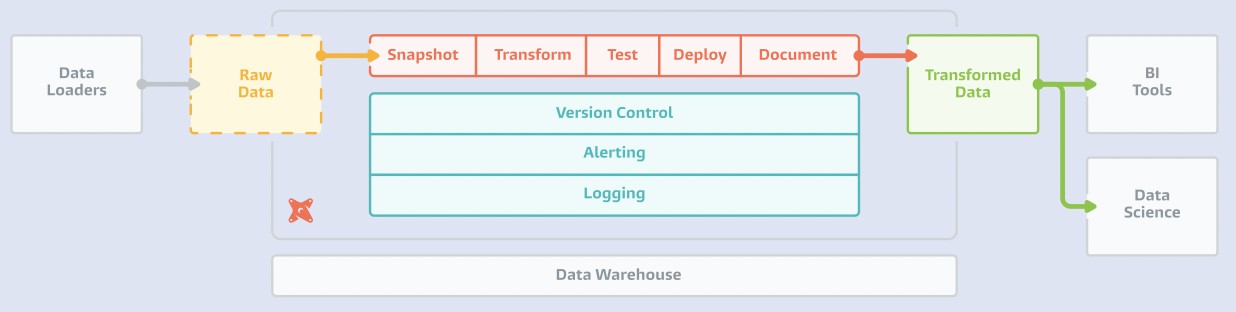
- Phase 1 — Assessment & Architecture: We audited the existing Pentaho-based ETL processes, documenting every transformation, business rule, and data dependency. This ensured zero business logic would be lost in the migration. We then designed a modern architecture using Python, dbt, and Apache Airflow — tools chosen for their reliability, community support, and suitability for Twinero’s scale.
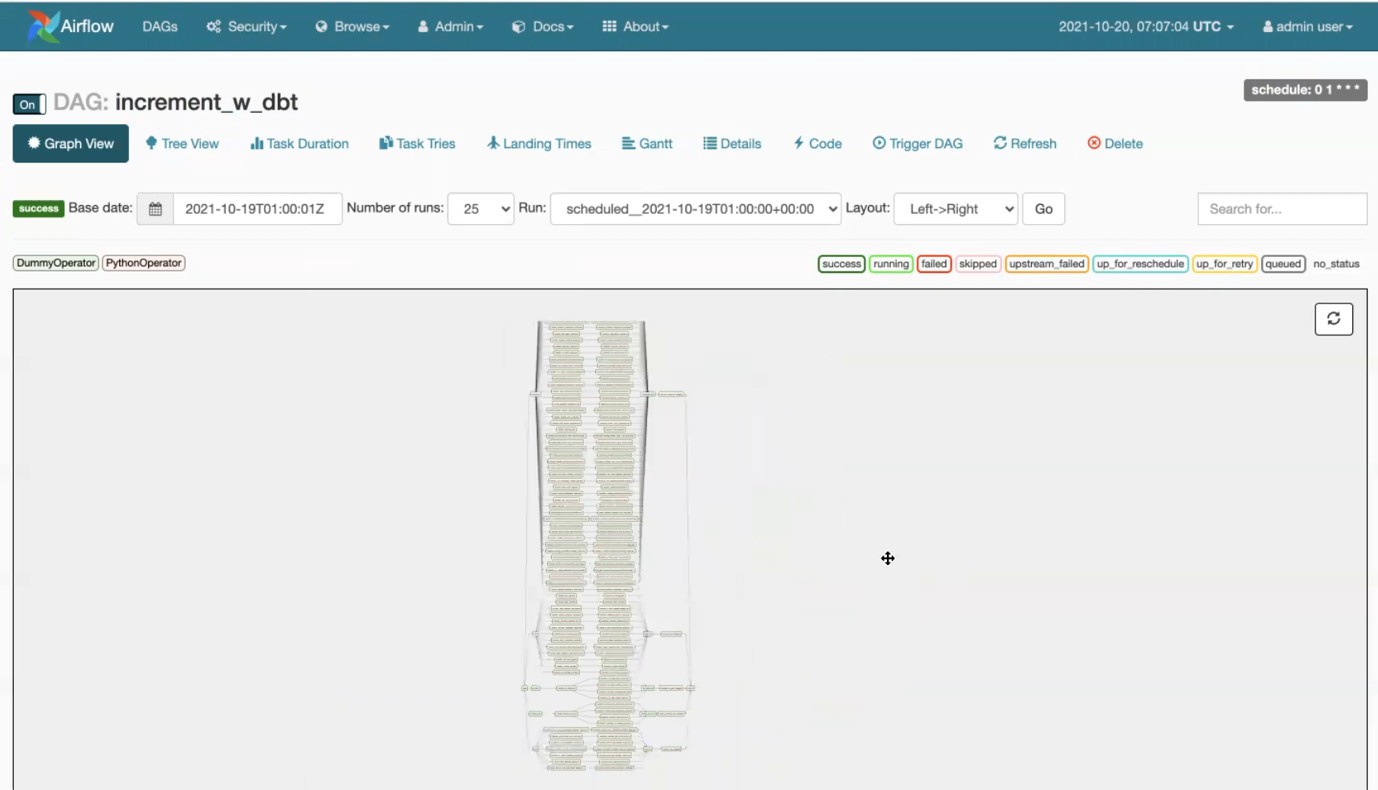
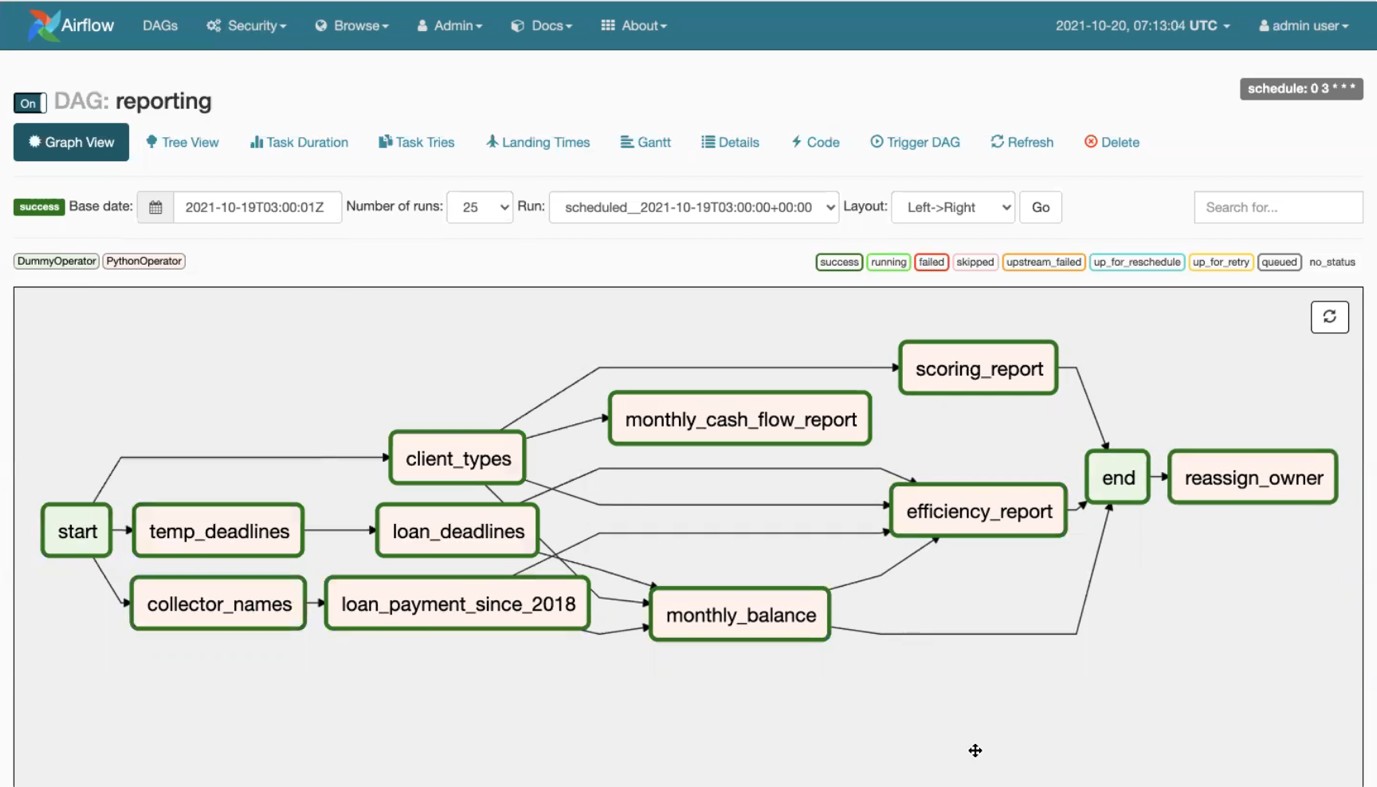
- Phase 2 — Migration & Implementation: We rebuilt each ETL pipeline in Python/dbt, implementing proper testing at each stage. The new pipelines included data quality checks, automated alerting for anomalies, and clear logging for troubleshooting. Apache Airflow was configured as the orchestration layer, replacing the fragile cron-based scheduling of the Pentaho system.
- Phase 3 — New Analytical Repository: Beyond migrating existing processes, we built a new analytical repository optimized for Twinero’s reporting needs. This included properly modeled data marts for loan portfolio analytics, risk metrics, and operational KPIs — structured to support both regular reporting and ad-hoc analysis.
We ran the old and new systems in parallel for two weeks, comparing outputs to ensure perfect data consistency before decommissioning the legacy infrastructure.
We paid special attention to the validation layer, implementing comprehensive data reconciliation checks that compared pipeline outputs against source system totals. For a fintech company, numerical accuracy isn’t approximate — loan balances, interest calculations, and risk metrics must be exact. We built automated reconciliation that ran with every pipeline execution, flagging any discrepancy above configurable thresholds. The team received a daily “data health” report showing pipeline status, record counts, and any quality issues — replacing the anxiety of not knowing whether reports were accurate with confidence backed by automated verification.
Results
- ETL processes running 5x faster than the legacy Pentaho system — SQL queries and table builds dramatically accelerated.
- Maintenance overhead reduced by approximately 60%, freeing the analytics team to focus on insight generation rather than pipeline debugging.
- Automated data quality checks catching errors before they reach reports — a significant improvement over the previous manual QA process.
- Modern, well-documented codebase that new team members can understand and extend without specialized legacy knowledge.
- Scalable architecture ready to support Twinero’s growth without requiring another rebuild.
Technologies Used
Python, dbt, Apache Airflow, PostgreSQL, SQL, automated testing frameworks.
Project Screenshots

Facing similar data challenges?
Book a Discovery Call →Key Takeaways
Perform reverse-engineering of all the created objects to find out how they work.
Abandon legacy code for an up-to-date solution for enhanced flexibility, performance, and scalability.
Data processing is best organized as separate manageable blocks. In this case, the engineering process is presented by a so-called pipeline or a consecutive transformation of raw data into manageable blocks. Such an approach allows spotting if there was a problem at each stage, as well as if the stage was implemented or not.
Have a similar challenge?
Let's talk about your data
A 30-minute conversation about your data stack, pain points, and opportunities.
Or email directly: nick@valiotti.com
Explore related projects

Built cohort-level ROAS tracking for a P2P investment platform. Channel-level visibility enabled confident 2-3x scaling of marketing spend with measurable…

Automated role-based dashboards for insurance executives, marketing, and agents. Eliminated 10+ hours/week of manual spreadsheet reporting and created a single…

Built 10+ custom Metabase dashboards for a global crypto platform's product and operations teams. Enabled cohort-level retention analysis critical for…